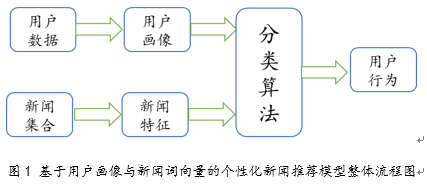
目前,由于用户行为数据的高维稀疏特点以及衡量新闻内容相似性的复杂度较高,本文针对这两个问题,从分类角度考虑,提出一种基于用户画像与新闻词向量的个性化新闻推荐模型,对用户的行为数据等进行分析,构建用户画像模型,提取用户画像特征,并使用指数衰减模型的Word2Vec框架进行词向量训练,结合文本特征的向量空间模型构建新闻全局特征,预测用户对新闻的行为――点击、不点击,从而将点击概率较高的新闻推荐给用户,提高推荐效果,可广泛应用于新闻门户网站,如人民网、网易新闻等。 随着互联网的迅速发展,用户获取信息的手段越来越便捷和丰富。为了缓解用户信息过载压力,推荐系统广泛应用于各类网站,包括电子商务[1]、、视频音乐网站[2]等等。由于用户个体的差异性,个性化推荐逐渐得到发展与采用。个性化推荐系统通过分析用户的历史信息和行为数据,预测用户兴趣爱好,从而向用户推荐感兴趣或潜在兴趣的信息,并针对不同的用户给出不同的个性化展示页面,以此来提高网站的点击率和收益。 目前常用的推荐算法主要分为三类:基于内容的推荐算法[3]、协同过滤推荐算法[1][4]以及混合推荐算法。这些传统的算法不需要经过训练,重点考虑用户之间的相似度和项目之间的相似度,评估用户对项目的兴趣度,进行排序后产生推荐结果。这些算法无法体现用户潜在的兴趣偏好,推荐的结果多样性不足[5]。同时,由于需要对用户的历史行为数据进行分析。用户的历史数据决定着最终的推荐结果。可是,用户的浏览、转发等行为存在大量的稀疏数据,通过这些高维稀疏数据难以计算出准确的相似用户群体。当两个用户没有对相同的项目评分,他们共同评分的集合数为0,那么即使他们的兴趣偏好非常相似,使用基于用户的协同过滤算法却不能求得他们之间的相似值,同样对于两个项目的属性非常相似,但是却没有共同用户对其进行评过分的情况,也无法使用基于项目的协同锅炉算法求得项目之间的相似性,导致无法有效的推荐。目前,由于对推荐系统的用户和项目信息庞大,其行为数据和评分信息异常稀疏,使得算法计算出的相似性不够准确,进而无法准确计算出目标用户的最近邻居集,导致推荐效果不佳。不仅如此,对于个性化新闻推荐模型,使用基于文档词频或文档逆频率特征的算法无法精准衡量不同类别新闻之间的相似性,导致推荐的结果大同小异,无法挖掘用户的潜在兴趣爱好,降低推荐效果。 针对上述问题,本文提出一种基于用户画像和内容词向量融合特征的个性化新闻推荐模型,分析用户的信息和历史行为数据构建用户画像,并使用改进的Word2Vec词向量训练算法对新闻内容进行训练,有效衡量新闻之间的相似性,进而采用高效分类算法预测用户对其推荐内容的行为――点击、不点击,并按照用户点击概率进行排序,将点击概率较高的新闻内容推荐给用户,这样避免衡量用户高维稀疏数据之间的相似性并能对新闻内容进行有效的特征提取,从而提高推荐效果,可广泛应用于新闻门户网站,例如人民网、新华网等。 本文从分类角度考虑用户对推荐新闻的态度,对其行为进行预测,能够有效利用用户的历史行为数据,包括用户点击、转发、评价等,将用户的历史点击行为为目标结果,能够有大量的数据进行算法训练,提高模型的精度。 1、对用户的基本信息和用户历史行为数据进行分析,构建相应的用户画像,建立用户的偏好模型,得到用户的融合特征; 2、采用改进的Word2Vec词向量训练算法对新闻语料库训练,得到更加精确的新闻词向量,并对新闻的内容、标题、领域、热度、时间等进行特征融合,从而获得相应新闻的融合特征; 3、由分类算法对用户和新闻的融合特征进行训练建模,预测该用户对相应新闻的行为,并得到用户点击该新闻的概率; 4、得到某一用户对众多新闻的点击概率后,使用Softmax归一化方法对其进行处理,获得用户点击概率较高的新闻,并推荐给用户。 本模型的整体流程如图1所示,模型采用的分类算法可采用目前进行且高效的深度森林[6](gcForest)、XGBoost[7]等,从而对用户的行为进行预测。本模型的重点和难点在于用户画像模型的构建以及采用改进的Word2Vec词向量获取新闻的融合特征。
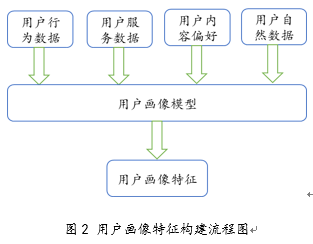
用户画像,即用户信息标签化,是通过收集与分析用户的社会属性、生活习惯、浏览行为等主要信息数据,抽象出的标签化的目标用户模型,通过综合用户的所有标签信息可勾勒出该用户的立体“画像”。 对于新闻推荐,用户的相关数据主要有网络行为数据、服务内行为数据、用户内容偏好数据、用户自然数据这四类。网络行为数据主要包括活跃人数、页面浏览量、访问时长、点击率等;服务内行为数据包括页面停留时间、访问深度、唯一页面浏览次数等;用户内容便好数据包括浏览内容、评论内容、互动内容、新闻类别偏好等;用户自然数据包括性别、年龄、地域、教育水平、职业等。 根据相关性原则,进一步筛选和构建用户画像目的相关的数据维度,避免过多无用数据干扰分析过程。对数据维度进行分解,形成字段集,再进一步将他们标签化及进行用户分群,构建基本用户画像。 通过真实的用户数据,建立用户的偏好模型,推测用户的标签,包括网站忠诚度模型,用户价值模型,用户活跃模型等等,通过模型的构建,对各用户贴上偏好标签。 结合用户的各偏好标签以及自然特征、兴趣特征等,将相关数据进行特征融合,构建出能够有效表示相应用户画像的特征向量。
传统的词向量表示方式为one-hot编码,即用一个很长的向量来表示一个词,向量的长度为词典的大小。向量的分量中该词对于在词典中的处为1,其他全为0。然而这种表示方式有两个显著的缺点:(1)维数灾难的困扰,且可扩展性差;(2)由于这种表示方式,任意两个词之间的词向量始终正交,不能很好地刻画词与词之间的相似性。 目前最常用的词向量训练框架为Word2Vec[8]算法,其CBOW+Hierarchical Softmax模型认为训练样本数目足够大时,上下文中的词对目标词预测的作用是线性衰减的。然而,在实际情况中,上下文中的词对目标词的预测作用随着与目标词距离的增大很快减小,不符合线性衰减规律。为了寻找更接近真实情况的衰减模型,文献[9]在对语料库中热词的上下文进行统计分析的基础上,采用若干种模型来拟合上下文对目标词预测作用的曲线,最后通过对比目标词的拟合误差,得到指数衰减拟合曲线对目标词的拟合误差最小。并通过实验验证了指数衰减模型构建的词向量在新闻分类任务中取得了更好的效果。因此,随着上下文中的词与目标词距离的变化,上下文对目标词预测作用是以指数的形式衰减。同时,在训练过程中,应合理的设置指数模型的超参数。
辞旧丹鸡鸣盛世,迎新瑞犬颂神州。新春佳节即将来临,人民网总编辑余清楚以及全国多家党报网站总编辑共同为网友们送上新春祝福!祝大家新的一年万事顺意,节节进步!
2017年,在习总网络强国战略思想下,网络安全和信息化工作各项工作扎实推进,网上主旋律高昂,正能量强劲,各项法律法规进一步完善,网络空间更加清朗,网络空间国际话语权和影响力明显提升。
|